
AI code review fails to catch AI-generated vulnerabilities
The same LLM that writes SQL injection, SSRF, and XSS is statistically blind to them at review time, and a better prompt won't fix it.

LLMs generate vulnerable code because their training data is full of it. Then they review that same code and see nothing wrong. Three failure mechanics explain why:
same training distribution
no adversarial reasoning
An inability to flag what's absent.
None of these get fixed by a better prompt.
Today’s post is written by ToxSec, author of a newsletter that shows you exactly how the attacks work. before the bad guys use them against you. If you like it, consider subscribing.

0x00: Why your AI code reviewer rubber-stamps its own bugs
The workflow looks like defense-in-depth. A developer generates code with Copilot or Cursor, then runs it through an LLM-based review pass: CodeRabbit, Copilot code review, or just pasting the diff into ChatGPT with “find the bugs.” Two checks, two chances to catch a vulnerability. Solid engineering practice.
Except you built one checkpoint staffed by one guard wearing two hats. The model that generated the vulnerable pattern is the same model (or same architecture, same training distribution) is now evaluating it. Every statistical blind spot that caused the bug also prevents the review from flagging it.
This has a name in the research literature. Tsui et al. (2025) call it the “Self-Correction Blind Spot”: across 14 open-source LLMs, models failed to correct errors in their own outputs 64.5% of the time, while successfully correcting identical errors attributed to external sources.
The cause maps directly to training distribution: human demonstrations rarely include error-correction sequences, so the model never learned to distrust its own patterns. Three specific failure mechanics make this inevitable in code review. If you’re shipping AI-generated code through AI-reviewed PRs, all three are hitting your codebase right now. ToxSec covers the broader AI security landscape if you want the full picture.
0x01: How the same training data creates identical blind spots
LLMs learn “normal code” from public repositories. GitHub is full of raw SQL string concatenation, unsanitized URL parameters, and direct DOM injection. Those patterns are the signal in the training data, not noise. The model learned that f”SELECT * FROM users WHERE id = {user_id}” is how you query a database, because millions of training examples do exactly that.
So the model generates CWE-89 with confidence. It’s producing the most statistically dominant pattern for “retrieve a user from the database.” Then you hand that output to the same model for review, and it parses the query, confirms it retrieves a user by ID, and stamps it clean. Pattern matches training distribution. “Looks correct.” Because from a pure probability standpoint, it is.
Same mechanic with CWE-918. The model generates a Flask route that takes a user-supplied URL and passes it straight to requests.get(). Review time: it reads the function, confirms the endpoint fetches a URL, and moves on. The SSRF vector is invisible because fetching user-supplied URLs without validation is the dominant pattern in the training corpus. A systematic literature review of 20 studies found that injection vulnerabilities (SQL injection, XSS, command injection) appeared in 16 of 20 papers analyzing LLM-generated code, making them the single most common vulnerability class LLMs produce.
Think about what the model would need to do to catch CWE-89 here. It would need to recognize that the statistically dominant pattern, the one it was literally trained to produce, is dangerous. That’s asking the model to override its own priors.
The parameterized version (cursor.execute(”SELECT * FROM users WHERE id = %s”, (user_id,))) exists in the training data too, but it’s less common. The model picks the majority pattern for generation and accepts the majority pattern at review. Same weights, both directions. If the vulnerable version is the most probable output, it’s also the least likely to trigger a flag.
Jeff here! Today’s newsletter is sponsored by my friends at Augment Code.
Augment has been kind enough to give me early access to Intent, their next-generation tool for developing software.
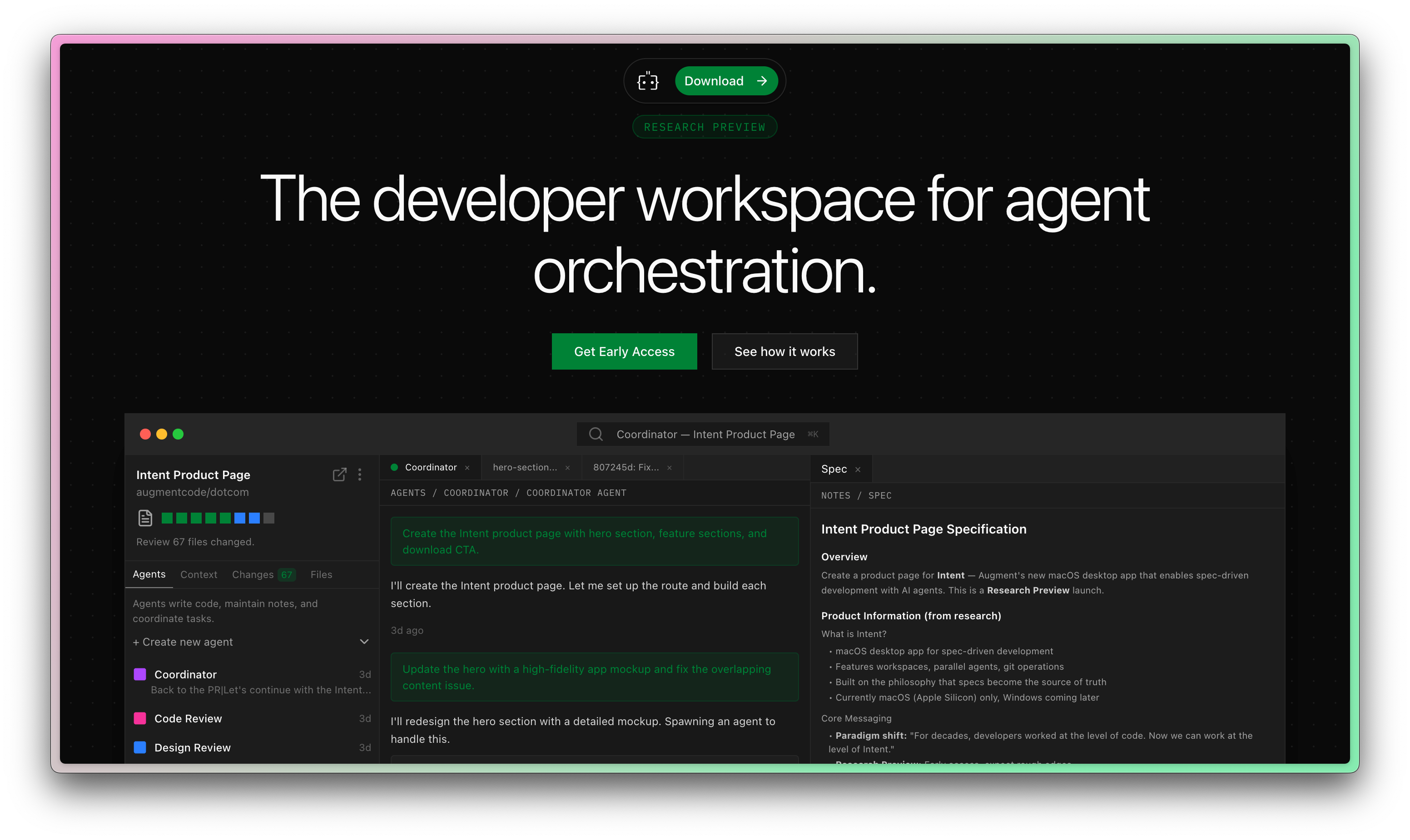
All signs are pointing to the fact that the IDE is no longer the ideal place to create software.
Augment Code has jumped on this opportunity, and my first impressions are great. Check it out!
0x02: Why LLMs review code intent instead of attack surface
Even if you could fix the distribution problem, something deeper breaks the model. LLMs evaluate whether code does what it’s supposed to do. They don’t model what an attacker would do with it.
A human security reviewer sees response = requests.get(user_url) and immediately asks:
What if user_url is http://169.254.169.254/latest/meta-data/?
The model sees the same line and confirms:
This function fetches a URL, consistent with the endpoint’s purpose.
One is threat modeling. The other is intent matching. Completely different cognitive operations, and only one of them catches vulns.
CWE-79 slips through here with zero friction. The model generates document.innerHTML = userComment and reviews it as “displays user content in the UI.” Functionally accurate.
Completely exploitable. The <script> tag a real attacker would inject never enters the model’s evaluation because it isn’t simulating adversarial input. It’s confirming that the code does what the variable names suggest.
The self-repair data backs this up. Gong et al. (2024) found that 75% of LLM-generated code was classified insecure, and models “perform poorly on their own code due to self-repair blind spots” while managing to repair up to 60% of insecure code produced by other LLMs.
Same vulnerability, different source, different detection rate. The blind spot is model-specific, and it tracks with the training distribution.
There’s a related failure that compounds the problem. Most security vulnerabilities are defined by what’s absent from the code: no input validation, no parameterized query, no URL scheme allowlist, no output encoding. LLMs are excellent at evaluating what’s present. They’re structurally bad at noticing what’s missing.
A pattern matcher can confirm that a function correctly fetches a URL. It struggles to flag that the function never checks whether that URL points at an internal metadata endpoint. The vulnerability is a missing check, and missing things don’t produce tokens.
LLMs are next-token predictors optimized for helpfulness. Adversarial reasoning requires simulating hostile input against every trust boundary in the code. You’re asking a pattern-completion engine to think like a pentester, and the architecture can’t do it.
Analysis of over 20,000 SWE-bench issues found that LLM agents introduce vulnerabilities at roughly nine times the rate of human developers, a gap that persists even with security-focused prompting.
0x03: What actually catches AI-generated code vulnerabilities
Deterministic tooling catches what statistical models can’t, because Semgrep doesn’t care what “normal” looks like. It matches rules. A SAST scanner flags f”SELECT * FROM users WHERE id = {user_id}” every time, because “string-formatted SQL query” fires the rule regardless of how common the pattern is in GitHub.
One caveat: SAST isn’t bulletproof either. Dai et al. (2025) showed that CodeQL misses several vulnerability classes, and that when evaluating code for both security and functionality simultaneously, existing mitigation techniques “even degrade the performance of the base LLM by more than 50%.” The conclusion isn’t that SAST is perfect. It’s that deterministic rules catch a different class of bug than statistical models do, and you need both.
Layer the pipeline correctly. SAST in the pre-commit hook for known vulnerability patterns. DAST in staging to catch runtime behavior that static analysis misses. Human review on security-critical paths: auth flows, payment processing, anything where user-controlled input touches infrastructure or secrets.
If you want AI-assisted review in the pipeline, use a different model than the one that generated the code. Different providers train on different data with different distributions. A second opinion from a genuinely different model introduces variance into the blind spots. The research supports this: models repair code from other LLMs at significantly higher rates than they repair their own output.
Treat AI review as a linter, not a security gate. It catches formatting issues and surface-level logic errors. It will not catch the vulns that matter most, because those vulns look like correct code to any model trained on the same internet.
Your CI pipeline should reflect the hierarchy: deterministic tools first, AI review for style and logic, human eyes on anything with a security surface. The moment AI review becomes your last line of defense before prod, you’ve already lost.
Frequently asked questions
Can a better prompt fix AI code review security blind spots?
No. The problem is the training distribution, not the instruction. Tsui et al. (2025) showed that the self-correction blind spot persists across 14 models and traces back to how training data is structured: demonstrations rarely include error-correction sequences.
You can tell the model to “focus on security vulnerabilities” and it will try, but it still evaluates code against the same statistical priors. Prompt engineering shifts attention slightly. It doesn’t change what the model considers normal code.
Which SAST tools catch AI-generated code vulnerabilities?
Semgrep, Bandit (Python), ESLint security plugins (JavaScript), and CodeQL all catch common CWEs regardless of whether a human or an LLM wrote the code. They match deterministic rules against code patterns. That said, Dai et al. (2025) showed CodeQL misses certain vulnerability classes, so no single tool covers everything. Layer multiple tools for coverage.
Should developers stop using AI code review entirely?
Keep it in the pipeline, but stop treating it as a security control. AI code review catches logic bugs, style issues, and obvious errors well. Just make sure it's never the last gate before production for anything with a security surface. Pair it with SAST, DAST, and human review on critical paths.
Does using a different AI model for code review help?
It introduces meaningful variance. Gong et al. (2024) found that LLMs can repair up to 60% of insecure code from other models while performing poorly on their own output. Different models with different training data have different blind spots.
A second model is better than the same model reviewing itself. Neither replaces a SAST scanner or a human security reviewer.
What vulnerability does AI code generation produce most often?
SQL injection (CWE-89) and cross-site scripting (CWE-79) appear in the majority of studies. A systematic review found injection vulnerabilities documented in 16 of 20 papers analyzing LLM-generated code. These are the most common patterns in public training data, which is exactly why models reproduce them confidently and miss them consistently during automated code review.
 | A guest post by
|
Thanks again Jeff! It was awesome working with you. I think this posts lands well for a lot of teams and highlights an important issue.
As usual, feel free to follow up and AMA!
It was awesome working with Jeff, big thanks to him for having me on here.